
Pathlight helps many companies improve the quality of customer support. One of the most common processes in customer support is Quality Assurance (QA). Graders and managers review and score an agent’s interaction with a customer. A company standardized rubric, the QA scorecard, is used to grade the interaction.
In July 2022, Pathlight users created more than 15,000 Quality Assurance (QA) scorecards to evaluate customer interactions. We wanted to increase the value that teams were getting with Pathlight QA by introducing an intelligence layer to enhance human evaluation. Typically, a customer support team can only QA ~2% of interactions so by providing enhanced intelligence tooling, we can help the graders more reliably and quickly evaluate interactions.
One of the intelligence improvements we implemented is QA Autograders. Autograders provide automatic scoring on certain aspects of a customer ticket, such as tone or keyword usage. The feature leverages natural language processing (NLP) to suggest scores on specific questions, while keeping the human in the loop.
Graders now have the ability to include Autograders with questions in the QA scorecard. The three different autograders currently available are Sentiment Analysis, Phrase Tracking, and Spelling and Grammar. Each Autograder had a unique creation and training process.
In this blog post, we will discuss the methodology for training and deploying the Autograders, as well as the challenges we encountered along the way!
Autograder Creation
Sentiment and Phrase Tracking were created using Deep Learning models and previous QA ticket data on Pathlight. The third Autograder, Spelling and Grammar, was created using external APIs, Python libraries and customization. In these next sections we will breakdown each Autograder and the specific approach we took for each one.
Sentiment Autograder
The goal here was to identify phrases where the agent used a very positive or negative tone. A QA grader will typically want to provide coaching on specific phrases in the interaction. Before we introduced the Autograders, individuals would read the entire agent-customer transcript multiple times to identify phrases with strong or weak sentiment. With QA Autograders sentiment analysis is much easier:
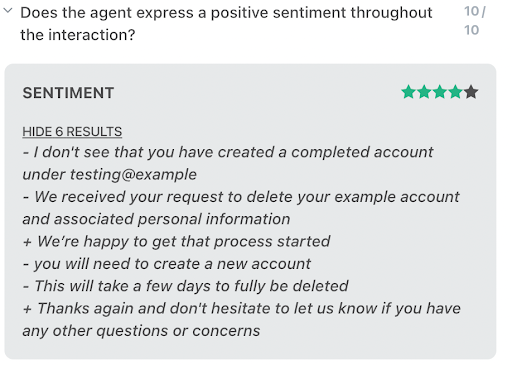
We utilized an incredible library, Huggingface, which makes state-of-the-art deep learning models available and easily accessible to the general public. The models help solve a range of problems: Image Classification, Object Detection, Translation and NLP. For Sentiment Analysis, we leveraged the NLP aspect of the platform, specifically the pipeline API.
Pipelines in Huggingface are similar to scikit-learn which allow the data cleaning, fitting, inference and evaluation to all happen via a single command. With Huggingface, we can specify a certain NLP task we want accomplished: here we choose “Sentiment Analysis”. The sentiment analysis pipeline is based on a framework from Google’s groundbreaking language model, BERT. We utilized this consolidated pipeline class along with transfer learning via in house algorithms and historical QA scorecards to ultimately create the Sentiment Autograder.
Phrase Tracking Autograder
One of the most common question graders want to answer is “Did the agent thank the customer for their time?”. This led to the creation of the Phrase Tracking Autograder which allows graders to input a set of phrases which are then identified in the text when the agent uses them.
Phrase Tracking was the most technically challenging autograder to build as it involved extensive NLP knowledge, as well as custom algorithms and logic. The algorithm performs both exact phrase matching as well as semantic similarity, internally dubbed as “Smart Matching”.
Smart Matching utilizes a NLP model created by Microsoft and accessed via Huggingface’s transformer library. The model takes a string of text as input and outputs a numeric vector. This vector represents the phrase’s position in a vector space of the English language. Next, we project the phrase entered by the grader and measure the cosine similarity between the two. Based on over 5,000 historical QA scorecards, we have an acceptance threshold of similarity for the algorithm to deem an agent’s phrase as “similar”.
The tricky part was deciding which agent phrase to measure with the inputted phrase. Here, we used an idea inspired by N-Grams:
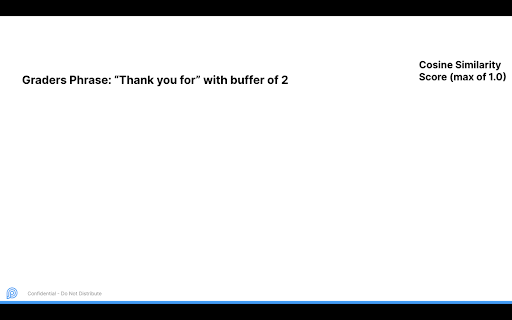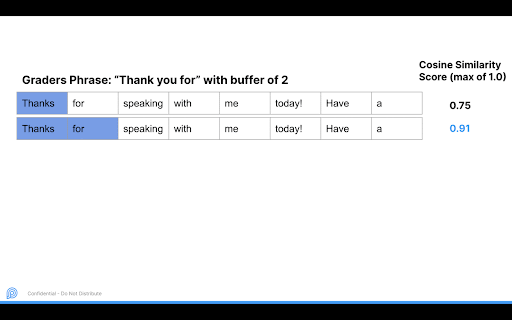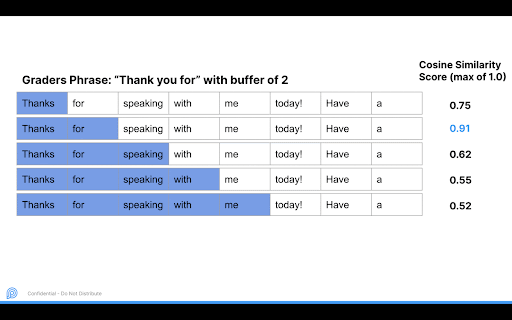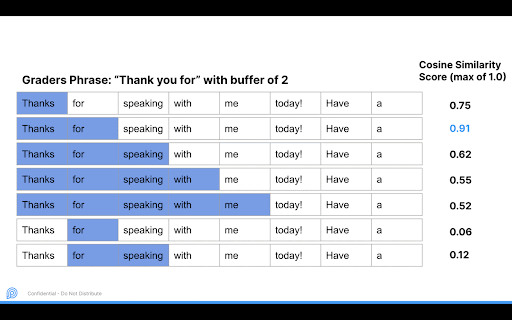
Based on the inputted phrase we would loop from 1 to the length of the phrase to match plus a buffer amount to be on the safe side. In the above example, “Thank you for” is the phrase to match, with length 3 and a buffer of 2, so we look at a max of 5 consecutive words. After looking at phrase length 1 to 5 we go to the next potential start word. Within each 1 to 5 iteration we only take the highest cosine similarity phrase, to avoid outputting substrings.
Spelling and Grammar Autograder
While communicating with a customer, professionalism and etiquette are essential for providing a positive customer experience. The final Autograder, Spelling and Grammar, aimed to help with this.
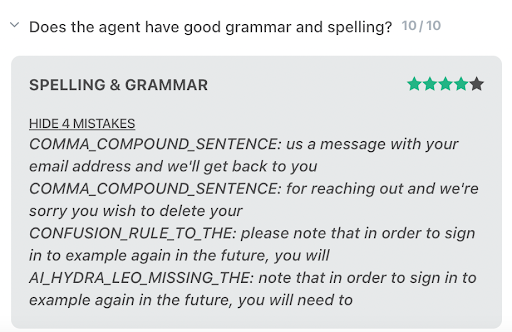
We utilized a Python wrapper for the Language Tool, a library used by Amazon, RingCentral, and many other companies. Additionally, we explored other spelling and grammar packages: pyspellchecker, textblob, inflect and autocorrect. As a result of this investigation, we decided to add another layer of confidence by using spellchecker in conjunction with the Language Tool for spelling mistakes. The extra package ensures we surface mispelled words according to multiple dictionaries. In the future, we also intend to expand the functionality of the Spelling and Grammar Autograder by incorporating company-specific terms and phrases, in order to better fit the use case of agents interacting with customers.
Autograder Deployment
We decided to host all Autograders on AWS Sagemaker as endpoints for the Pathlight App to access. The models’ memory sizes are too large to be packed into the web app’s Docker Container Image. Second, separating the Autograders and web app allow for easier re-deployment and model monitoring. Finally, the AWS EC2 instance used on the website is not optimized for model inference as it does not contain GPUs, so we created a separate and serverless endpoint:
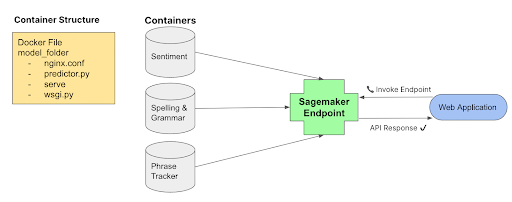
While doing this, we wanted to ensure it was easy for the application side of things to call and ingest the model inferences:
import boto3
from sagemaker import get_execution_role
#Create client
deployment_name = "autograders"
sm_client = boto3.client(service_name='sagemaker')
runtime_sm_client = boto3.client(service_name='sagemaker-runtime')
request_body = {"inputs": agent_transcript}
#Serialize data for endpoint
data = json.loads(json.dumps(request_body))
payload = json.dumps(data)
#Endpoint invocation
response = runtime_sm_client.invoke_endpoint(
EndpointName=f"autograders-ep",
ContentType="application/json",
Body=payload,
TargetContainerHostname="sentiment")The client interface is exactly the same for all of three Autograders and any future Autograders and the only difference is to vary TargetContainerHostname. The response from the endpoint is also standardized and flexible for future Autograders. A lists of lists is returned where each element of the list follows the structure [agent_paragraph_number, agent_text, result]:
print(response)
[[1, 'welcome to Pathlight thank you for visiting, 'POSITIVE'],
[4, 'have a fantastic day', 'POSITIVE']]Autograders were the first external API built at Pathlight and had unforeseen challenges. The problems incurred were related to building in an environment which was completely separate from our existing production environment. After the first iteration, the Autograders were not even callable due to a version issue with the production side’s boto3 package. With all these learnings, we created a dedicated testing environment on the endpoint side, which is similar in nature to a staging environment. This ensures the API invocation is seamless for the application.
Future of Autograders
The three existing Autograders have already had great impact on the QA product at Pathlight. We have seen a lot of excitement from existing and potential customers, who quickly understood the utility that Autograders would bring to their process.
Now that we have built a stable infrastructure and deployment process, we can easily expand our suite of Autograders to provide even more value to the grading experience. Next steps will be to improve the Autograders as more customers use them.
We will improve via customer feedback and more automated training cycles. For example, the grammar errors currently given are not very human readable as exemplified by the Spelling and Grammar screenshots above. There are over 5,000 errors returned by Language Tool, which are too many to manually parse. We plan to track the most common grammar errors to decide which of the errors are useful to parse. Another enhancement to the spelling and grammar Autograder will be a company specific dictionary.
Finally, a more overarching improvement will be to implement continuous training. As customers continue to utilize Autograders, we can use their answer selections in conjunction with the Autograder’s outputs to enhance future Autograder outputs.